

The AI-optimized drivers landscape overview

Tuning operational parameters on a modern GPU is a highly complex hardware/software problem that requires not only a high degree of specialization but also exhaustive human effort to achieve, at times, negligible improvements. Thus, it is no surprise that the use of machine learning to address driver optimization challenges is becoming an important trend.
Applying machine learning techniques to build an optimization model offers an elegant solution to this problem, providing a robust means of automatically learning nonlinear decision functions in high-dimensional spaces. In this brief overview, we will analyze how each of the two main players in the GPU market is leveraging AI to optimize their drivers, highlighting the current stage of development and the different forms of application.
The Nvidia Approach
Fine-tuning the operating parameters of a modern GPU is highly complex, requiring significant human effort to generate hard-coded heuristic solutions, often limited to a specific set of workloads and parameters, which are inefficient for real-time hardware tuning operations.
To address this real-time optimization challenge on their GPUs, Nvidia has proposed a neural network-based optimization approach capable of selecting an optimal set of performance monitoring values based on constraints that consider both computational cost and latency, which is set to be implemented in the Blackwell architecture.
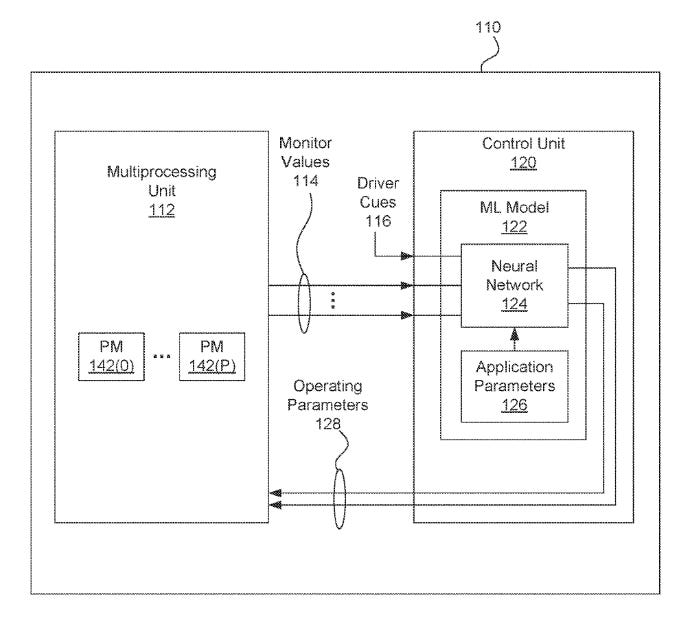
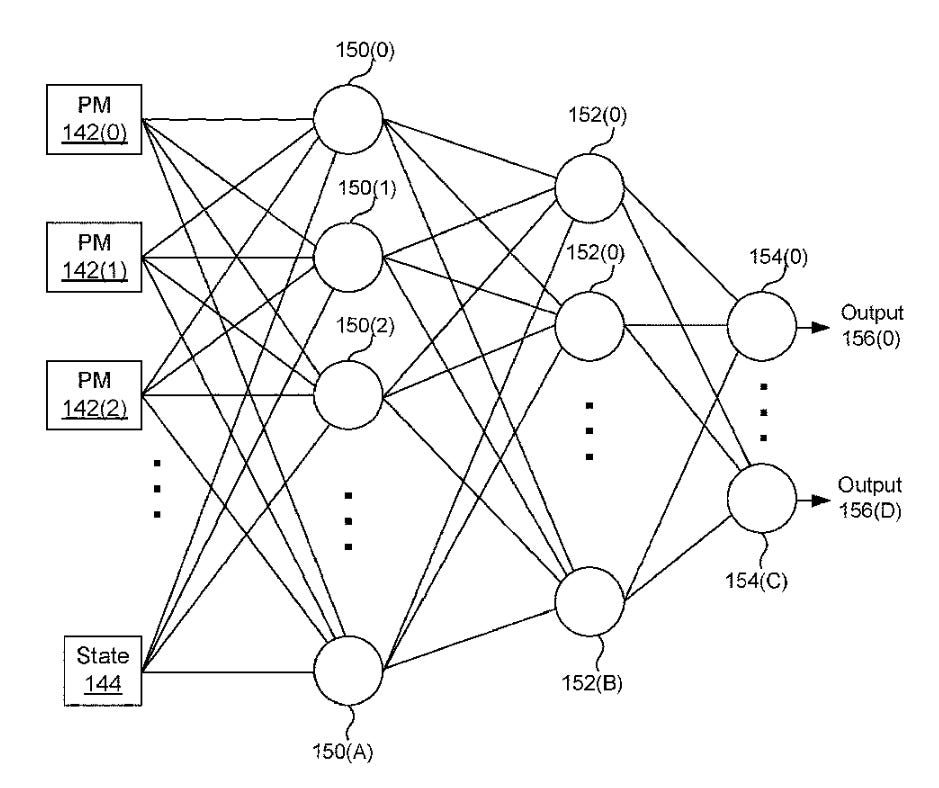
The core idea behind this proposal is that the GPU's internal control unit implements a neural network subsystem configured to receive the application state, current operating parameter state, and driver cues as inputs. As performance monitoring values change during application execution, the neural network provides feedback, updating the operating parameters to optimize the GPU's ongoing operation.
The current state of operational parameters is measured in real-time to record specific statistics related to application execution. These statistics include memory request count, memory system bandwidth utilization, memory system storage capacity utilization, cache hit rate, instructions executed per clock cycle for one or more threads of the multithreaded program, and the total count of executed instructions for the threads.
Driver cues include suggestions from the driver, such as increasing or decreasing a specified clock frequency or enabling/disabling tile caching. These cues are generated by the driver through certain optimization methods and heuristics, but the control unit is configured to determine whether to accept a given driver cue suggestion.
The application parameters are determined during offline training of the neural network subsystem for each application and potentially for each operating mode of a given application. This enables the realization of the long-awaited real-time "fine wine" hardware tuning optimization in games, which other heuristic-based methods cannot achieve.
To reduce computational effort in a real-time scenario, it is clear that tensor cores will play a crucial role in the effective implementation of this method. At this point, it also becomes evident why Nvidia has made several continuations of this patent over the years. A historical analysis of the patent suggests that this method could have been implemented as early as the Ampere generation. The fact that it is only being implemented now with Blackwell indicates that Nvidia's motivation goes beyond simply delivering more performance, with a stronger focus on effectively improving power efficiency.
Finally, it is important for the reader to understand that there are a multitude of optimization methods and approaches using machine learning. Nvidia's approach, which focuses on fine-tuning hardware parameters, is not the only viable method for achieving the "fine wine" of optimization. For example, machine learning-based optimization can also be applied to software tuning, as AMD has already proposed in its research.
The AMD approach
Modern GPU drivers implement a variety of operations when compiling shader programs to improve performance, and over the years, this has been the primary Achilles' heel of AMD's GPU development.
Since the performance improvements associated with these compiler operations are often highly sensitive to hardware changes, new driver versions frequently need to be released to adjust how and when compiler operations are performed to enhance game performance. These driver tweaks are carried out by skilled engineers who exhaustively explore the code optimization space using iterative trial and error, which demands significant expertise as optimizations grow more complex over time. Yet, even with such effort, these methods often fail to uncover more intricate optimization patterns.
To address this problem and finally bring the fine-grained compile adjustments needed to maximize GPU performance, AMD researchers have proposed a GPU compiler auto-tuning framework that leverages off-policy deep reinforcement learning (DRL) to generate heuristics that enhance the frame rates of graphics applications, thus reducing the effort required to update compilers while maximizing shader program performance.
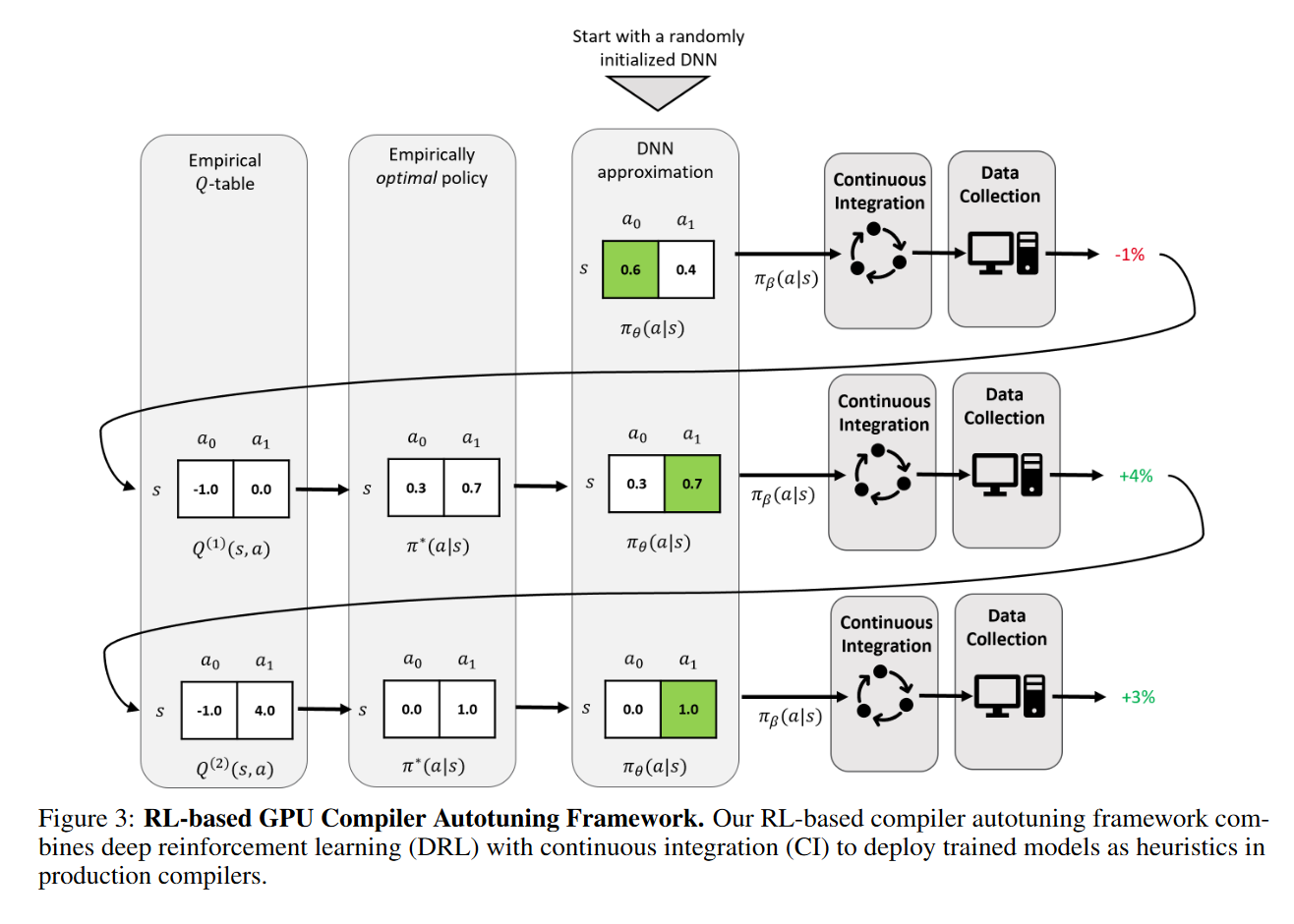
The training strategy is based on a Q-learning approach, which seeks to optimize a Q-table to maximize the expected frame rate improvement when applying specific heuristic settings to given states. Once trained offline, the learned model is integrated directly into the compiler to act as a heuristic decision function. The learned parameters are periodically deployed as a behavior policy to collect performance measurements and update the empirical Q-table through a DRL trial-and-error feedback loop.
By reintroducing corrective feedback and alleviating data collection bottlenecks, this training strategy can learn stable heuristics that are both resilient to the ever-evolving nature of production software and generalizable across graphics benchmarks and GPU targets.
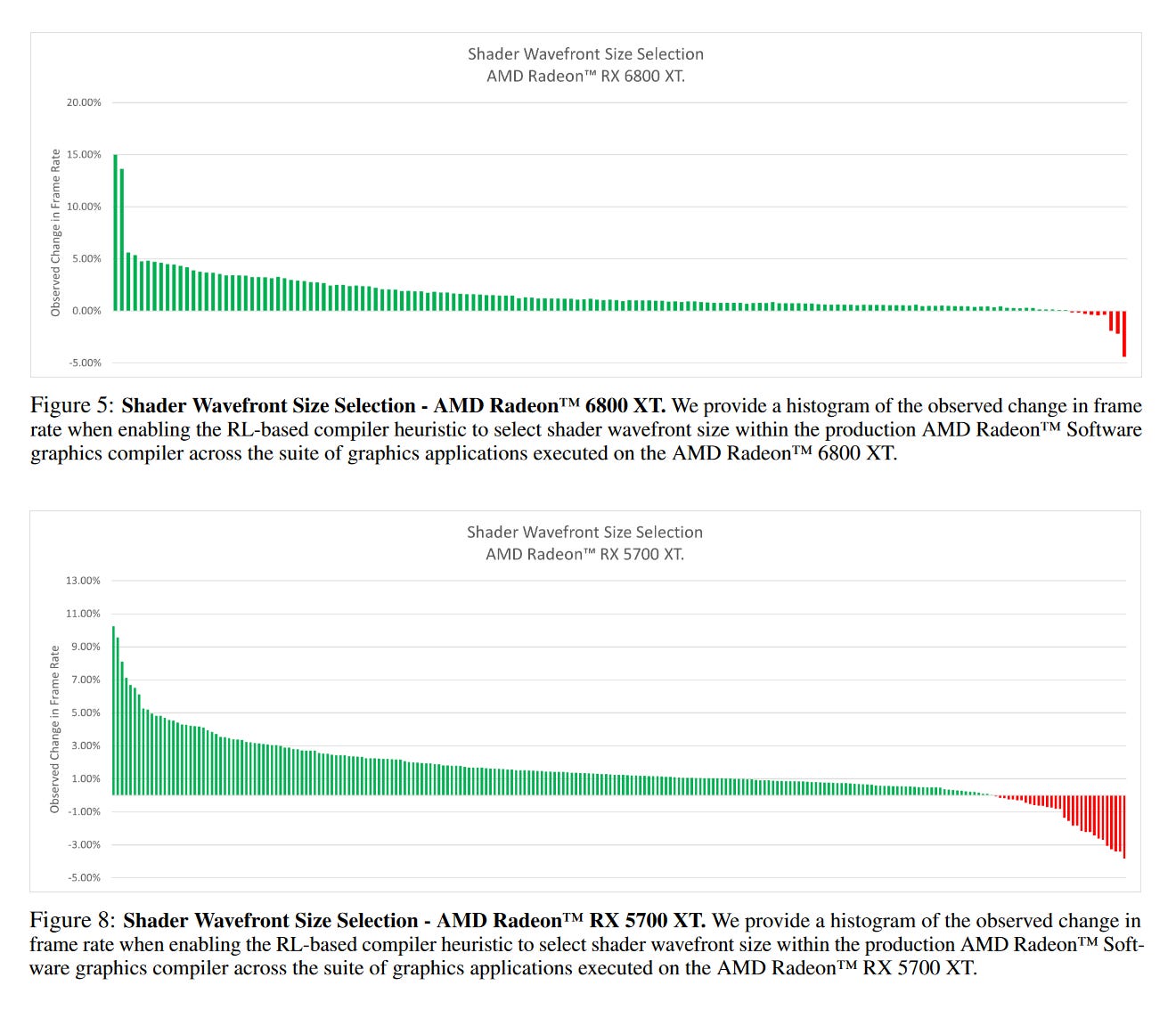
The results of this new approach proposed by AMD reveal how effective such a framework can be in achieving the much-desired "fine wine" game optimization, showing that, compared to the standard compiler, the proposed DRL compiler auto-tuning framework matches or exceeds frame rates for 98% of graphics benchmarks, with an average uplift of 1.6% (and up to 15.8% in some cases). These figures may seem modest at first glance, but they represent an exceptional result. The baseline comparison used a fully tuned production driver that had already been optimized by AMD's team of experts, leaving little room for further improvement.
This work was, to the best of my knowledge, the first ML-based auto-tuning framework designed to learn, integrate, and deploy heuristics in a production GPU compiler. However, after several attempts by AMD to patent this technique, it was abandoned by the company last year, clearly reflecting AMD's lack of interest in this matter and its preference to focus efforts in ML on HPC, which is a shame.
Some references and further reading:
US10909738 - Real-time hardware-assisted GPU tuning using machine learning - Dimitrov et al. - Nvidia [Link]
Ian Colbert, Jake Daly, Norm Rubin,Generating GPU compiler heuristics using reinforcement learning, Arxiv, (2021) [Link]
US20210065441 - Machine learning-based technique for execution mode selection - Colbert et al. - AMD [Link]
Changelog
v2.0 - Redesigned the article originally published on post.news to be more compatible with Substack. Figures remain unchanged;
Donations
Monero address: 83VkjZk6LEsTxMKGJyAPPaSLVEfHQcVuJQk65MSZ6WpJ5Adqc6zgDuBiHAnw4YdLaBHEX1P9Pn4SQ67bFhhrTykh1oFQwBQ
Ethereum address: 0x32ACeF70521C76f21A3A4dA3b396D34a232bC283